Agents
- Agent: perceives environment with sensors, acts on it with actuators
- Percept: what sensors detect
- Percept sequence: history of all percepts an agent has ever received
- Agent function: maps percept sequence → action
- Agent program: concrete implementation of agent function
- Rational agent: chooses action expected to maximize performance measure given percepts + knowledge
- Performance measure: defines success (objective, e.g., dirt cleaned, safety, cost)
- rationality ≠ omniscience or perfection → just maximize expected performance
Agent examples
- human agent: eyes/ears/etc. for sensors, hands/legs/etc. for actuators
- robotic agent: cameras, infrared, motors
- software agent: inputs = keystrokes/files/packets; outputs = screen, files, packets
- environment: only the relevant part of the universe affecting perceptions/actions
PEAS framework
- Performance measure, Environment, Actuators, Sensors
- must define PEAS to design rational agent
- examples:
- vacuum agent: perf = clean squares, env = rooms, acts = suck/move, sens = dirt/location
- internet shopping agent: perf = price/quality/efficiency, env = vendors/shippers/websites, acts = click/fill form/display, sens = html pages
- automated taxi: perf = safety/speed/legal/profit/comfort, env = roads/traffic/police/weather, acts = steering/brake/accel/horn/etc., sens = cameras/gps/radar/etc.
- medical diagnosis: perf = healthy patient/minimize cost, env = patient/hospital, acts = display/tests/referrals, sens = touchscreen/voice input
- interactive tutor: perf = max student test score, env = students/testing agency, acts = display/exercises/feedback, sens = keyboard/voice
- part-picking robot: perf = % parts binned correctly, env = conveyor + bins, acts = robotic arm, sens = camera/tactile sensors
Environment types
-
fully vs partially observable: all relevant info available or not (taxi = partial, chess = full)
-
deterministic vs stochastic: next state fully determined or probabilistic
-
episodic vs sequential: one-shot decisions vs decisions affect future
-
static vs dynamic: environment stays fixed vs changes during deliberation
-
discrete vs continuous: finite vs infinite states/time/percepts/actions
-
single vs multi-agent: only one agent vs multiple (competitive/cooperative)
-
simplest environment: fully observable, deterministic, episodic, static, discrete, single-agent
-
real world: partially observable, stochastic, sequential, dynamic, continuous, multi-agent
Agent types
four kinds:
- simple reflex
- model-based reflex
- goal-based
- utility-based
- all can be turned into learning agents
Table-lookup agent (bad)
- huge table → infeasible memory
- long to build
- no autonomy
- cannot learn all entries from experience
Simple reflex agent
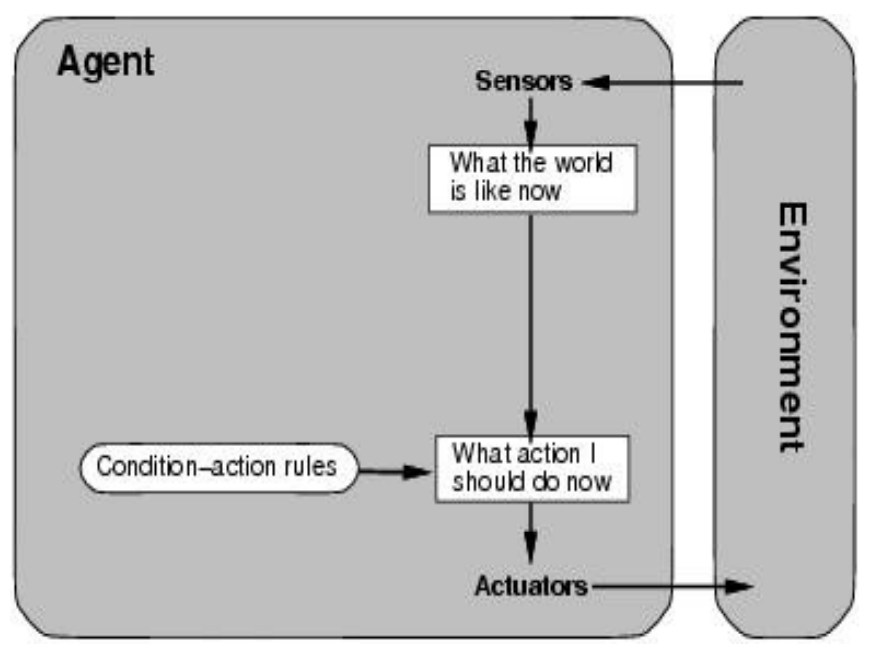
rectangles = current internal state of agent’s decision process, ovals = background info
- action only depends on current percept
- implemented via condition-action rules (e.g., if dirty → suck)
- works only in fully observable environments
Pseudocode:
function SIMPLE-REFLEX-AGENT(percept) returns an action
static: rules, a set of condition-action rules
state <- INTERPRET-INPUT(percept)
rule <- RULE-MATCH(state, rule)
action <- RULE-ACTION[rule]
return actionModel-based reflex agent
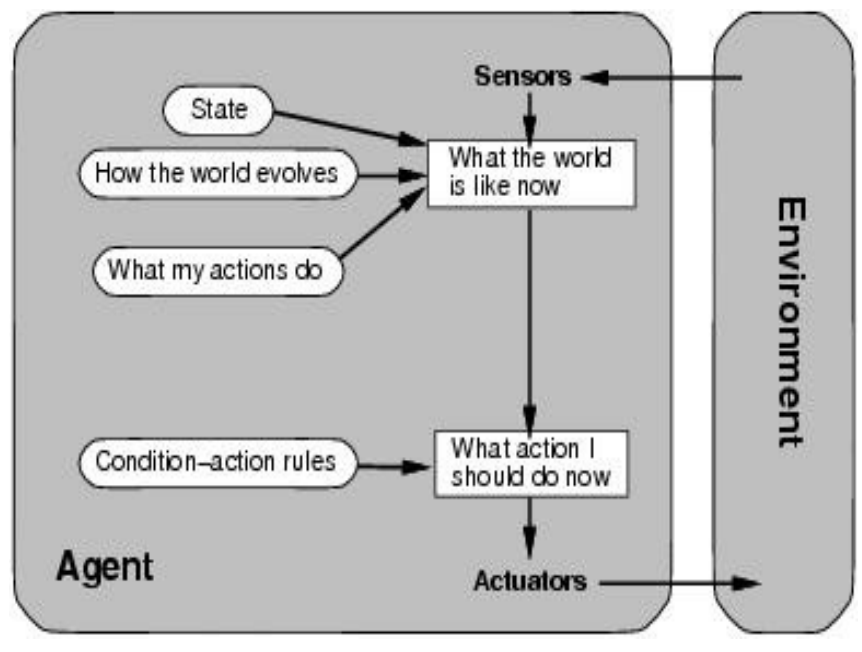
- used in partially observable environments
- maintains internal state updated by percept history + world model
- tracks unobservable parts of world
Goal-based agent
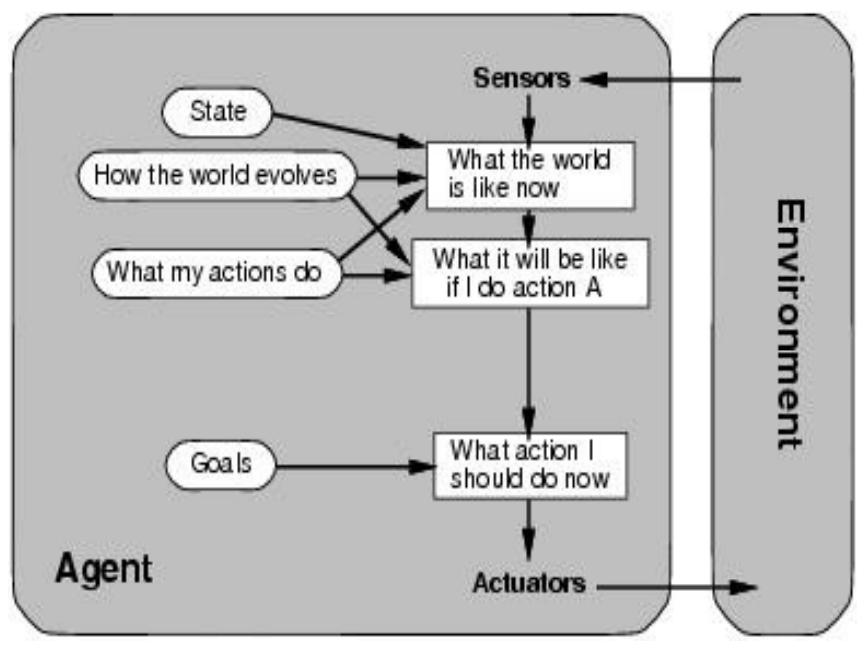
tracks world state + goals, chooses action that leads to goal achievement
- needs a goal to know desirable states
- considers future sequences of actions
- tied to search/planning research
- more flexible, explicit knowledge representation
Utility-based agent
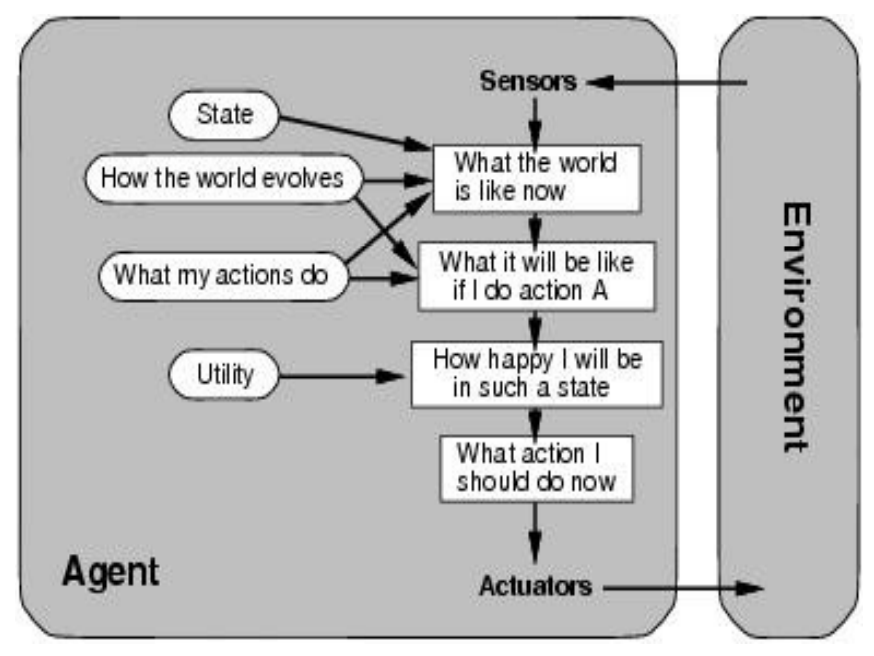
uses world model + utility function that measures preferences among states
- some goals achievable in different ways; some better
- utility function: maps states → real number
- handles conflicting goals, picks based on success likelihood
Learning agent
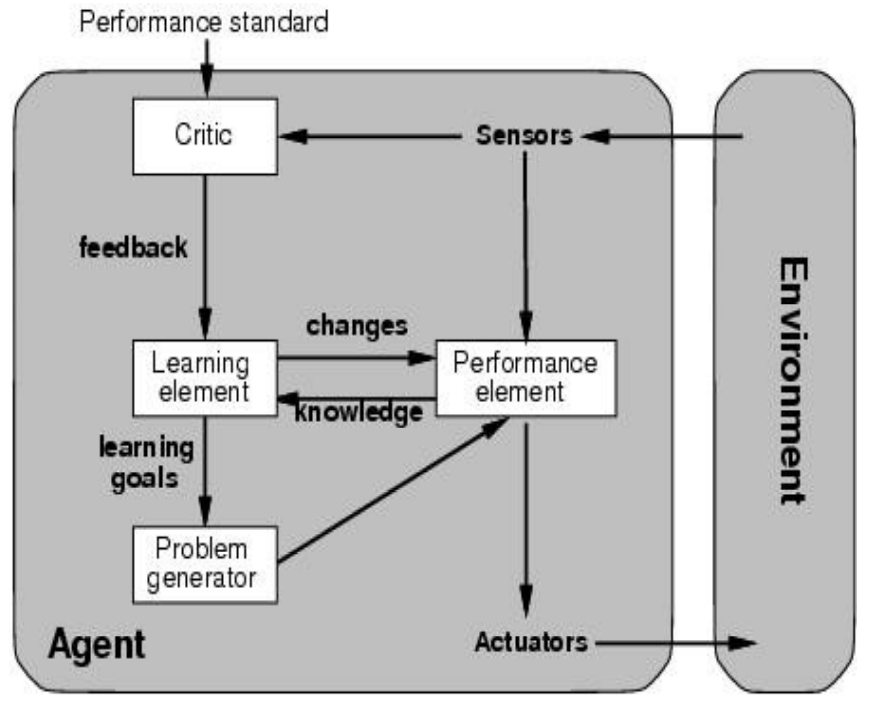
- earlier agents = action selection only, no origin of program
- learning element: improves performance element, critic gives feedback
- performance element: picks actions (core agent)
- problem generator: suggests exploratory actions (explore vs exploit)
- benefit = robustness in unknown environments
Supervised & unsupervised learning
Supervised
- “teacher says yes or no”
- training data has expected outcome
Unsupervised
- only training data, no expected outcome
- e.g., clustering or classification in its own way
Problem-solving agents
- extend goal-based agents into problem-solving agents
- must specify:
- what goal needs to be achieved (task, situation, or properties)
- how to know when goal is reached (goal test)
- who specifies the goal (designer or user)
Problem-solving cycle
- goal formulation – define desirable states
- problem formulation – identify states and actions relevant to goal
- search – find sequence of actions that reaches goal
- execution – carry out the actions
flowchart TD A[Goal formulation] --> B[Problem formulation] B --> C[Search for solution] C --> D[Execute actions]
Search problems
- a search problem defined by:
- state space (all possible states)
- successor function (actions and their costs)
- start state and goal test
- a solution = sequence of actions (plan) from start to goal
example: romania travel
- state space: cities
- successor: roads with distance costs
- start: arad
- goal test: is state bucharest?
- solution: path of cities (e.g., arad → sibiu → fagaras → bucharest)
graph TD Arad --> Sibiu Arad --> Zerind Sibiu --> Fagaras Sibiu --> Rimnicu Fagaras --> Bucharest Rimnicu --> Pitesti Pitesti --> Bucharest
Single-state problem formulation
- initial state (e.g., arad)
- successor function S(x) = set of action–state pairs
- e.g., S(arad) = {arad→zerind, arad→sibiu, …}
- goal test: explicit (at bucharest) or implicit (checkmate)
- path cost: additive; step cost c(x,a,y) ≥ 0
- solution: sequence of actions from start to goal
- optimal solution: lowest path cost
| Element | Example |
|---|---|
| Initial state | Arad |
| Successor function | S(Arad) = {Arad→Zerind, Arad→Sibiu, …} |
| Goal test | at Bucharest |
| Path cost | distance, # of actions |
Selecting a state space
- real world too complex → must use abstraction
- abstract state = set of real states
- abstract action = bundle of real actions (e.g., “arad→zerind” covers many routes)
- abstraction valid if it preserves solution paths
- abstract solution = set of real paths
- each abstract action should be simpler than real problem
Example problems
- vacuum world
- states: 2 locations, dirty/clean
- actions: {left, right, suck}
- goal test: no dirt
- path cost: number of actions
stateDiagram-v2 [*] --> LeftDirty LeftDirty --> LeftClean: Suck LeftClean --> RightDirty: Move Right RightDirty --> RightClean: Suck RightClean --> Done: all clean
- 8-puzzle
- states: positions of 8 tiles + blank
- actions: {up, down, left, right}
- transition model: action → new state
- goal test: reach target configuration
- path cost: number of actions
- note: only half of all possible initial states lead to goal
graph TD Start[Initial state] --> Move1[Move blank left] Start --> Move2[Move blank up] Move1 --> Goal[Target configuration] Move2 --> ...
- 8-queens
- states: 0–8 queens on board
- actions: add queen to safe square
- goal: 8 queens, none attacked
- path cost: often irrelevant
graph TD EmptyBoard[0 queens] --> Q1[Add queen column 1] Q1 --> Q2[Add queen column 2 (non-attacking)] Q2 --> Q3[Add queen column 3 ...] Q3 --> Goal[8 queens placed safely]
-
chess
- states: all board positions
- actions: legal moves
- initial: standard chess start
- goal: checkmate opponent
-
robot assembly
- states: joint angles + object parts
- actions: continuous motions
- goal test: complete assembly
- path cost: execution time
flowchart TD Init[Initial arm position] --> Move[Joint motion] Move --> Partial[Partial assembly] Partial --> Complete[Goal: full assembly]
Real-world example problems
- route finding (networks, travel planning, military ops)
- touring problem
- traveling salesman problem
- vlsi design (chip layout and routing)
- robot navigation
- automatic assembly sequencing
Basic search algorithms (intro)
- how to solve the above problems? → search state space
- generate search tree:
- root = initial state
- children = successors
- in practice, search generates a graph (states may be reached by multiple paths)