Shared-memory programming with OpenMP
Note
Starting at
l7Oa.pdfslide 45
Private variables
int x = 5;
#pragma omp parallel num_threads(thread_count) private(x)
{
int my_rank = omp_get_thread_num();
printf("Thread %d > before initialization, x = %d\n", my_rank, x);
x = 2 * my_rank + 2;
printf("Thread %d > after initialization, x = %d\n", my_rank, x);
}
printf("After parallel block, x = %d\n", x);What is the output of this code?
Solution
Trick question, we cannot tell. The value of
xis unspecified:
- at the beginning of the parallel (for) block
- after the completion of the parallel block
The default Clause
- allows the programmer to specify the scope of each variable of a block
default(none)- it is good practice to specify the scope of each variable in a bock explicitly
- with this clause, the compiler will require that we specify the scope of each variable we use in the block and that has been declared outside the block
double sum = 0.0;
# pragma omp parallel for num_threads(thread_count) \ default(none) reduction(+:sum) private(k, factor) \ shared(n)
for (k = 0; k < n; k++) {
if (k % 2 == 0)
factor = 1.0;
else
factor = -1.0;
sum += factor / (2 * k + 1);
}Note
End of
l7Oa.pdf, moving on tol7Ob.pdf
Bubble sort
for (list_length = n; list_length >= 2; list_length--) {
for (i = 0; i < list_length - 1; i++) {
if (a[i] > a[i + 1]) {
tmp = a[i];
a[i] = a[i + 1];
a[i + 1] = tmp;
}
}
}Odd-even transposition sort
- basically parallel bubble sort
- repeatedly compares and swaps adjacent elements in two phases: even phase and odd phase
- process repeats until no more swaps are needed → list is fully sorted
// Serial odd–even transposition sort skeleton
for (phase = 0; phase < n; phase++) {
if ((phase % 2) == 0) {
for (i = 1; i < n; i += 2)
if (a[i - 1] > a[i]) Swap(&a[i - 1], &a[i]);
} else {
for (i = 1; i < n - 1; i += 2)
if (a[i] > a[i + 1]) Swap(&a[i], &a[i + 1]);
}
}Thread pooling
- in OpenMP: depends on implementation
- Intel OpenMP creates pool of threads form the beginning
- forking threads and building a thread pool
- with parallel directive: tells OpenMP to use the team of threads for parallelizing the for loops
OpenMP odd-even sort
// Odd–even transposition sort (parallel with OpenMP)
for (int phase = 0; phase < n; phase++) {
int i, tmp;
if ((phase % 2) == 0) {
#pragma omp parallel for num_threads(thread_count) \
default(none) shared(a, n) private(i, tmp) schedule(static)
for (i = 1; i < n; i += 2) {
if (a[i - 1] > a[i]) {
tmp = a[i - 1];
a[i - 1] = a[i];
a[i] = tmp;
}
}
} else {
#pragma omp parallel for num_threads(thread_count) \
default(none) shared(a, n) private(i, tmp) schedule(static)
for (i = 1; i < n - 1; i += 2) {
if (a[i] > a[i + 1]) {
tmp = a[i + 1];
a[i + 1] = a[i];
a[i] = tmp;
}
}
}
}with thread pooling:
#pragma omp parallel num_threads(thread_count) \
default(none) shared(a, n) private(i, tmp, phase)
{
for (phase = 0; phase < n; phase++) {
if ((phase % 2) == 0) {
#pragma omp for schedule(static)
for (i = 1; i < n; i += 2) {
if (a[i - 1] > a[i]) {
tmp = a[i - 1];
a[i - 1] = a[i];
a[i] = tmp;
}
}
} else {
#pragma omp for schedule(static)
for (i = 1; i < n - 1; i += 2) {
if (a[i] > a[i + 1]) {
tmp = a[i + 1];
a[i + 1] = a[i];
a[i] = tmp;
}
}
}
// implicit barrier here ensures threads sync before next phase
}
}Performance
- odd-even sort with two parallel for directives and two for directives
- times are in seconds
thread_count | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| two parallel for directives | 0.770 | 0.453 | 0.358 | 0.305 |
| two for directives | 0.732 | 0.376 | 0.294 | 0.239 |
Scheduling loops
- in parallel for directive: the exact assignment of loop iterations to threads is system dependent
- most OpenMP implementations → the default behaviour
- roughly → a block partitioning
- n iterations in the serial loop
- parallel loop the 1st n/thread_count → assigned to thread0
- roughly → a block partitioning
Optimal split?
no! uneven distribution on inexact assignments, meaning thread
thread_count-1will do more work thanthread0.Better (more evenly distributed) assignment? → round robin fashion
yes! cyclic partitioning of iterations
To parallelize this loop:
sum = 0.0;
for (i = 0; i <= n; i++)
sum += f(i);
double f(int i) {
int j, start = i * (i + 1) / 2, finish = start + i;
double return_val = 0.0;
for (j = start; j <= finish; j++) {
return_val += sin(j);
}
return return_val;
} /* f */Assignment of work using cyclic partitioning
| Thread | Iterations |
|---|---|
| 0 | |
| 1 | |
Results
f(i)calls thesinfunctionitimes- assume the time to execute
f(2i)requires approx. twice as much time as the time to executef(i)
| n | thread # | assignment type | run-time | speedup |
|---|---|---|---|---|
| 10000 | 1 | 3.67s | ||
| 10000 | 2 | default | 2.76s | 1.33s |
| 10000 | 2 | cyclic | 1.84s | 1.99s |
- a good assignment of interactions to threads → significant effect on performance
The schedule clause
default schedule
sum = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+:sum)
for (i = 0; i <= n; i++)
sum += f(i);cyclic schedule
sum = 0.0;
#pragma omp parallel for num_threads(thread_count) \
reduction(+:sum) schedule(static,1)
for (i = 0; i <= n; i++)
sum += f(i);schedule(type, chunksize)
- type can be:
- static: iterations can be assigned to the threads before the loop is executed
schedule(static, 1)- thread 0: 0,3,6,9
- thread 1: 1,4,7,10
- thread 2: 2,5,8,11
schedule(static, 2)- thread 0: 0,1,6,7
- thread 1: 2,3,8,9
- thread 2: 4,5,10,11
schedule(static, 4)- thread 0: 0,1,2,3
- thread 1: 4,5,6,7
- thread 2: 8,9,10,11
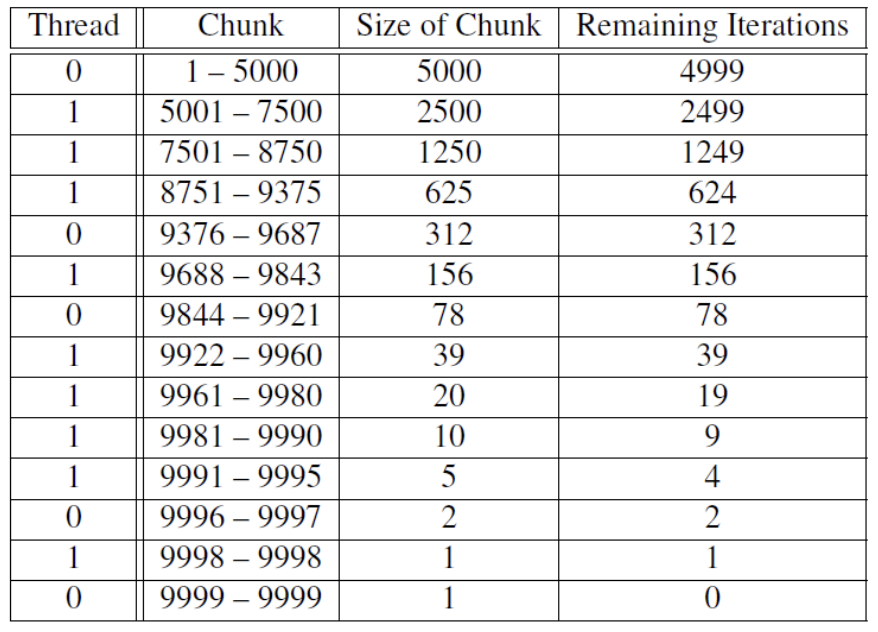
- dynamic/guided: iterations are assigned to the threads while the loop is executing
- dynamic: when a thread finishes a chunk, it requests another one from the run time system
- guided: same as above, but as chunks are completed, the size of the new chunks decrease
- auto: compiler and/or the run-time system determines the schedule
- runtime: schedule is determined at run time
- uses the environment variable
OMP_SCHEDULEto determine at run time how to schedule the loop OMP_SCHEDULEcan take on any of the values that can be used for a static, dynamic, or guided schedule
- uses the environment variable
- static: iterations can be assigned to the threads before the loop is executed
- chunksize is a positive integer